こんにちは。今回はAWS LambdaでSeleniumを使ったスクレイピングを行い、画面キャプチャを保存する方法と使用したソースコードを紹介します。
他にも記事を挙げている方がおり、かぶってしまう内容もありますが、ハマりポイントがいくつかあったのでその紹介と、具体的な手順をメインにお伝えします。
また、本記事ではLambdaの編集はAWS Cloud9で行っています。
Cloud9を使用することでLambda Functionの編集がやりやすくなり保守性が高まるのでオススメです。
キャプチャ保存までの仕組み
本記事で紹介する仕組みの構成は以下のようになります。
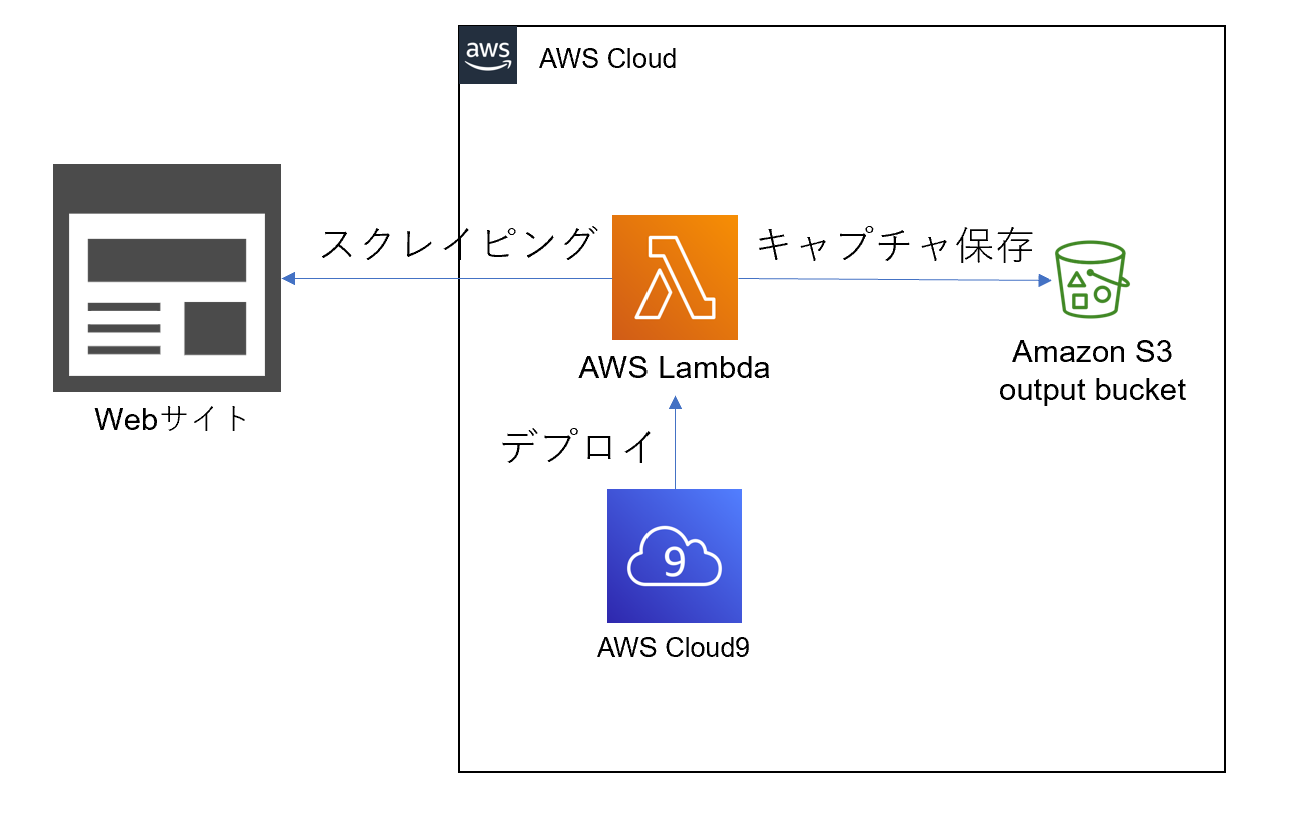
こちらの構成を実現するうえでポイントとなるのは以下の通りです。
- ブラウザがない環境でChromiumを使用してブラウザを使用した時のような操作をする(ヘッドレス Chromeを使用する)
- Lambdaの一時領域に画面キャプチャを保存し、S3に転送する
- 画面キャプチャの日本語の文字化けを解消する
手順1:Cloud9でLambda Functionを作成する
まずはLambda Functionの作成から始めます。
Cloud9の画面の右側に以下のようなLambda Functionの作成ボタンがあるのでそこから作成します。
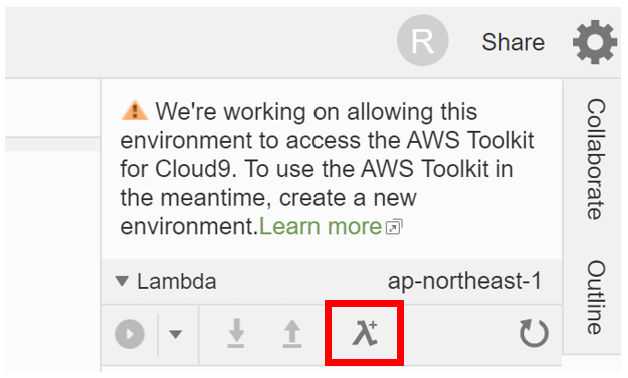
Lambda Function作成時の設定は以下の通りです。
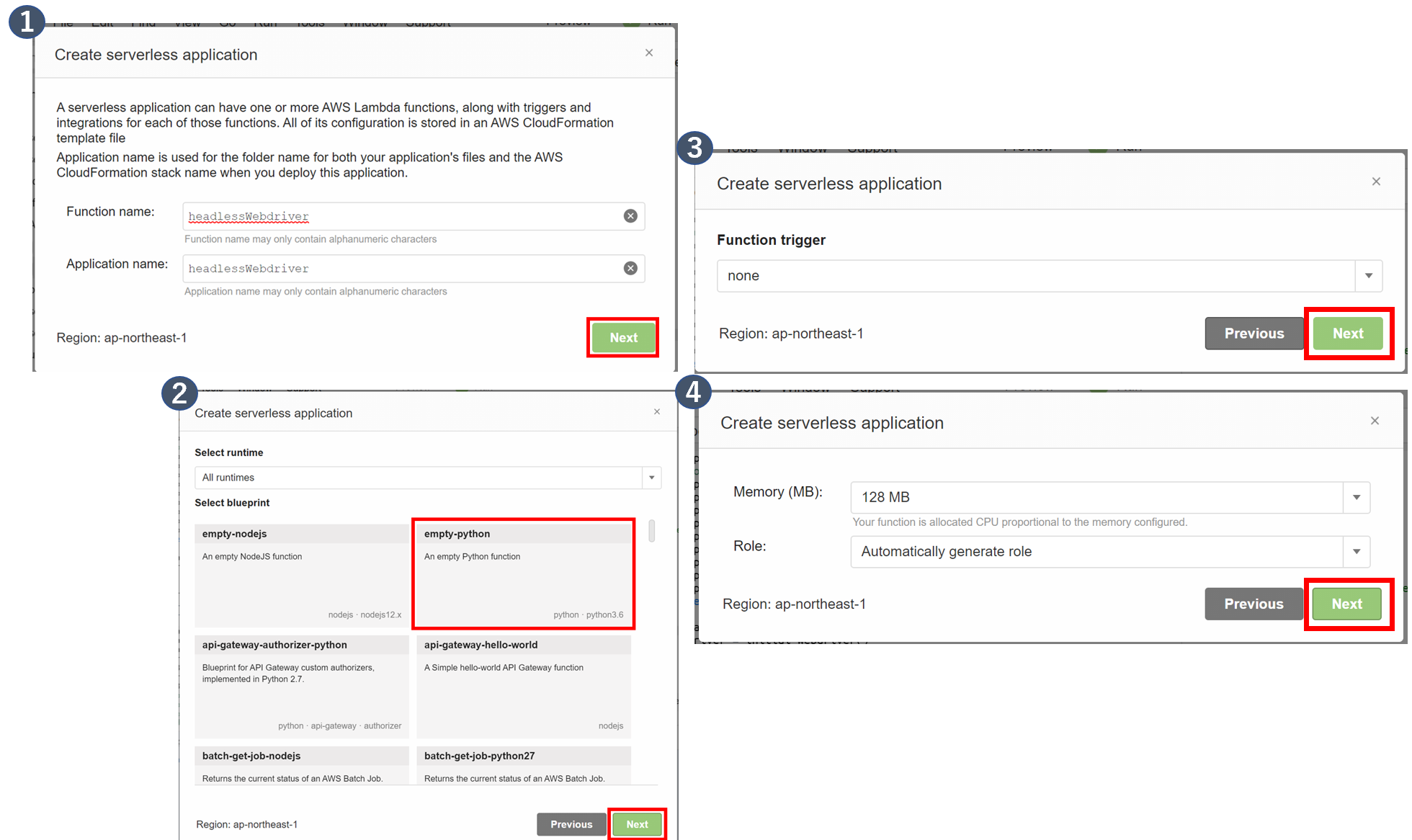
- Function名:任意
- blueprint:enpty-python
- Trigger:None
- Memory:任意(※)
※ ポイントとなるため、以下で解説
Lambdaリソースのポイント
Memoryは512Mb程度をオススメします。少ないと時間がかかってタイムアウトになってしまいます。
手順2:headless-chromiumとchromedriverの入手
headless-chromiumのダウンロード
headless-chromiumのgithubからheadless-chromiumをダウンロードし、zipを解凍すると「headless-chromium」が出てくるので、Cloud9の任意のディレクトリにアップロードします。
ただし、手順1でLambda Functionを作成した際にFunction名と同様のディレクトリが作成されたと思いますが、そのディレクトリ配下のどこかにしてください。
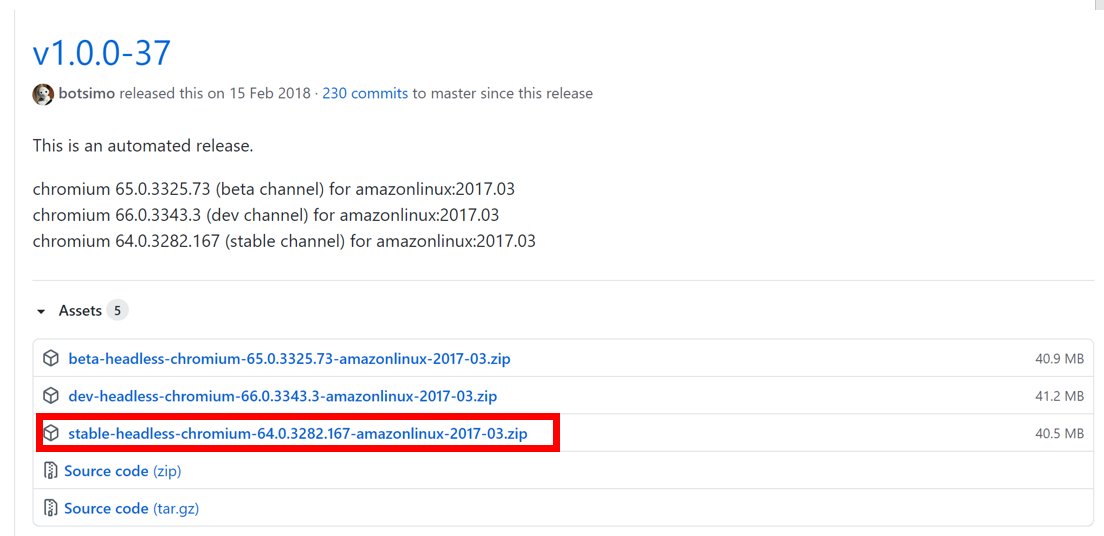
本記事では例として、「function名ディレクトリ/bin」ディレクトリに配置します。
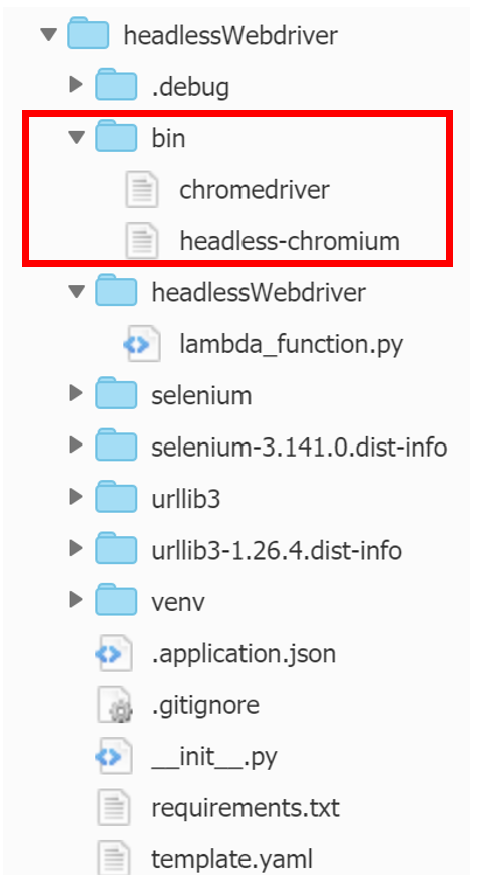
chromedriverのダウンロード
こちらのリンクからchromedriverをダウンロードし、zipを解凍すると「chromedriver」が出てくるので、上記のheadless-chromiumを配置したディレクトリに配置します。

headless-chromiumとchromedriverのポイント
headless-chromiumとchromedriverのバージョンの組み合わせは重要です。
互換性のないバージョン同士だと動作しないため、動作の確認ができているバージョンを使用することをオススメします。
上記に紹介したバージョンは動作確認済みです。
権限変更
headless-chromiumとchromedriverの権限を変更しておく必要があります。
どちらも755に権限変更してください。
$cd bin
$sudo chmod 755 *手順3:seleniumのインストール
Pythonライブラリであるseleniumをpipインストールします。
手順1で作成されたディレクトリ配下で下記コマンドを実行します。
$ pip install --target=./ selenium手順4:ソースコードの記述
手順1で作成したLambda Function名と同様のディレクトリの中に、さらにLambda Function名と同様のディレクトリがあるはずです。

そちらのディレクトリ内にlambda_function.pyファイルがあるので、下記のソースコードを記載します。
from selenium import webdriver
import boto3
S3_BUCKET_NAME="XXXXXXXX"
SNAPSHOT_NAME="XXXXXX.png"
ACCESS_KEY = "XXXXXXXXXXXXXXXXXXXX"
SECRET_ACCESS_KEY = "XXXXXXXXXXXXXXXXXXXXX"
HEADLESS_CHROMIUM_PATH="./bin/headless-chromium"
CHROME_DRIVER_PATH="./bin/chromedriver"
def initial_webdriver():
options = webdriver.ChromeOptions()
options.binary_location = HEADLESS_CHROMIUM_PATH
options.add_argument("--headless")
options.add_argument("--disable-gpu")
options.add_argument("--window-size=1280x1696")
#options.add_argument("--disable-application-cache")
options.add_argument("--disable-infobars")
options.add_argument("--no-sandbox")
options.add_argument("--hide-scrollbars")
options.add_argument("--enable-logging")
options.add_argument("--log-level=0")
options.add_argument("--single-process")
options.add_argument("--ignore-certificate-errors")
options.add_argument("--homedir=/tmp")
options.add_argument('--user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.150 Safari/537.36')
return webdriver.Chrome(CHROME_DRIVER_PATH, chrome_options=options)
def lambda_handler(event, context):
driver = initial_webdriver()
# Webサイトにアクセス
driver.get("https://wellknowledge.org/")
#Seleniumで行う処理を記載
s3 = boto3.client('s3', aws_access_key_id=ACCESS_KEY, aws_secret_access_key=SECRET_ACCESS_KEY)
driver.save_screenshot('/tmp/'+SNAPSHOT_NAME)
s3.upload_file(Filename="/tmp/"+SNAPSHOT_NAME, Bucket=S3_BUCKET_NAME, Key=SNAPSHOT_NAME)
return''
ソースコードの変更箇所は以下です。
- S3_BUCKET_NAME:キャプチャした画像を配置するS3のバケット名
- SNAPSHOT_NAME:キャプチャした画像の任意の名前
- ACCESS_KEY:S3へのアップロード権限を持ったIAMのアクセスキー
- SECRET_ACCESS_KEY:S3へのアップロード権限を持ったIAMのシークレットキー
- HEADLESS_CHROMIUM_PATH:headless-chromiumのパス
- CHROME_DRIVER_PATH:chromedriverのパス
※ キャプチャした画像を配置するS3のバケットはあらかじめ作成しておいてください。
※ 上記サンプルソースではLambda Functionのディレクトリ配下にbinディレクトリを作成し、そこにheadless-chromiumとchromedriverを配置したときのパスを記載しています。
手順5:Lambda Functionのデプロイ
ソースが作成出来たら、画面右側のファンクション名を選択し、「↑」をクリックすることでデプロイできます。
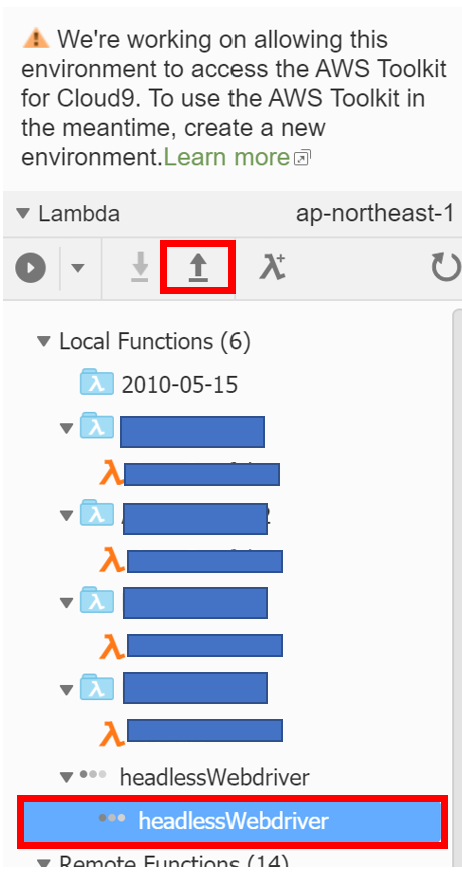
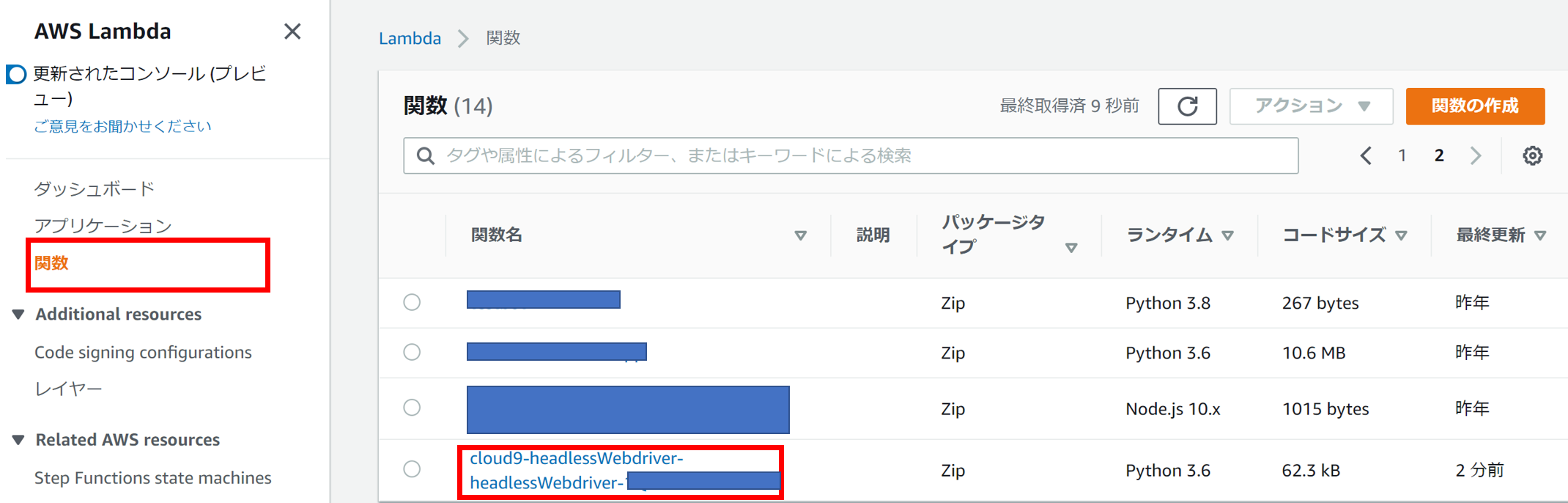
デプロイすると、AWSコンソールのLambdaの画面からデプロイされた関数を確認できます。
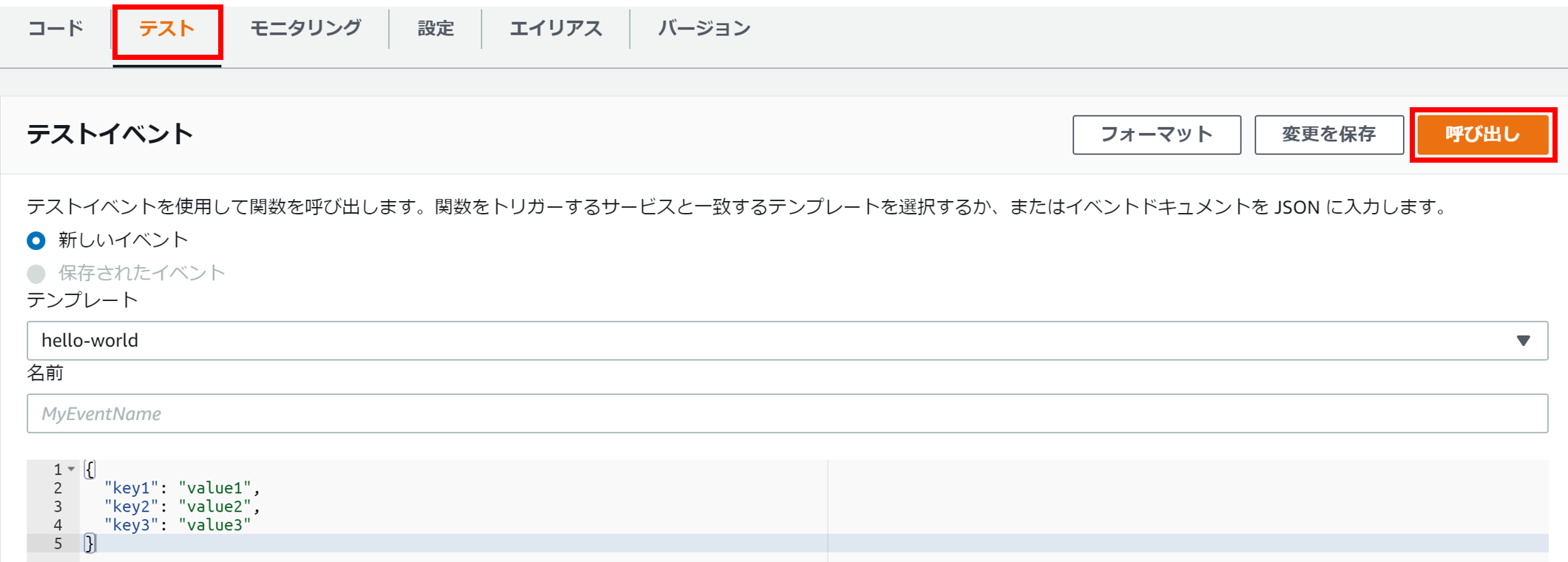
試しにテストを実施
これでスナップショットを撮れるハズ!ということで、試しにテストします。
テストは、先ほどの関数で作成した関数のリンクをクリックした先で以下の「テスト」タブから実行できます。
テスト結果
以下のようにスナップショットが取れています。
しかし、日本語がうまく表示されないことが分かると思います。。
日本語が表示されないポイント
日本語が表示されない原因はLambdaの実行環境に日本語フォントがないためです。
そこで、日本語サイトをスクレイピングする際には下記手順で日本語フォントを追加する必要があります。
手順6:日本語フォントを設定
フォントのダウンロード
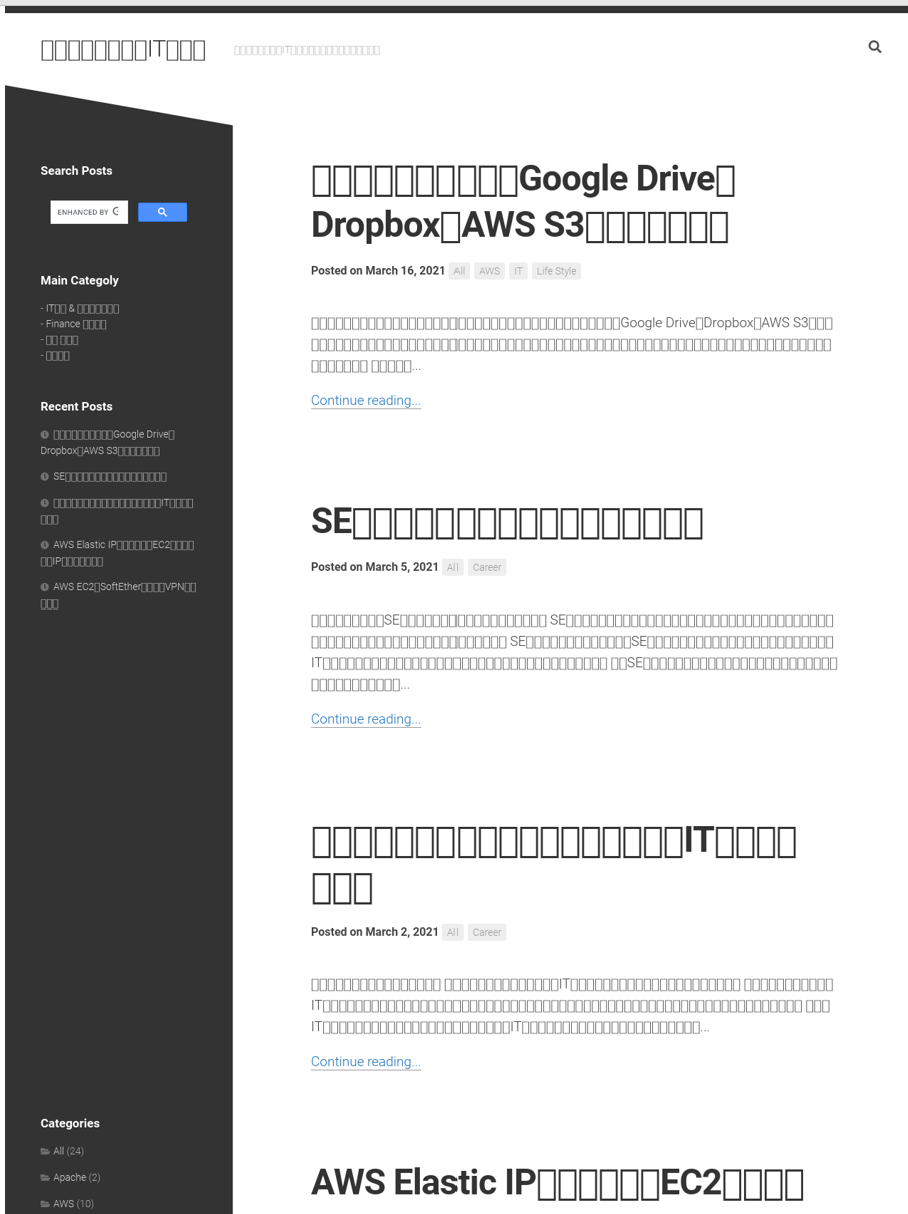
日本語フォントはIPAが提供しているIPAex明朝とIPAexゴシックを使用します。
こちらから以下のフォントパックをダウンロードします。
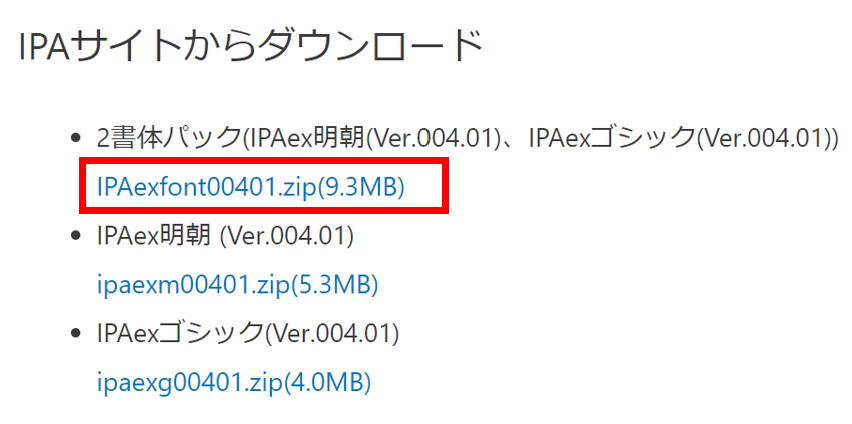
zipを解凍すると以下の中身が出てきます。

Lambdaにアップロードするためzipに固める
AWS Lambdaでは「レイヤー」としてあらかじめ準備したファイルをアタッチして使用することができます。
fontを認識してもらえるよう、「.fonts」ディレクトリとしてアタッチする必要があります。
そのため、「.fonts」ディレクトリを作成し、上記の「ipaexg.ttf」、「ipaexm.ttf」ファイルを入れてzipに固めます。
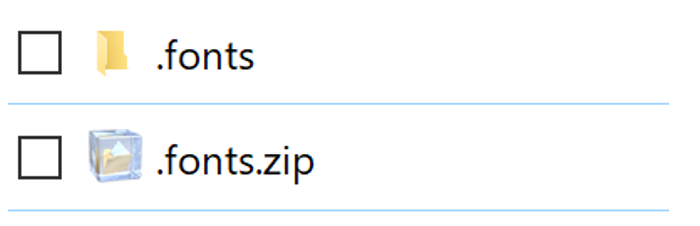
AWS Lambda レイヤーを作成する
Lambdaのコンソールから「レイヤー」を選択し、「レイヤーの作成」を行います。
レイヤーを作成する際に先ほど作成した「.fonts.zip」ファイルをアップロードします。
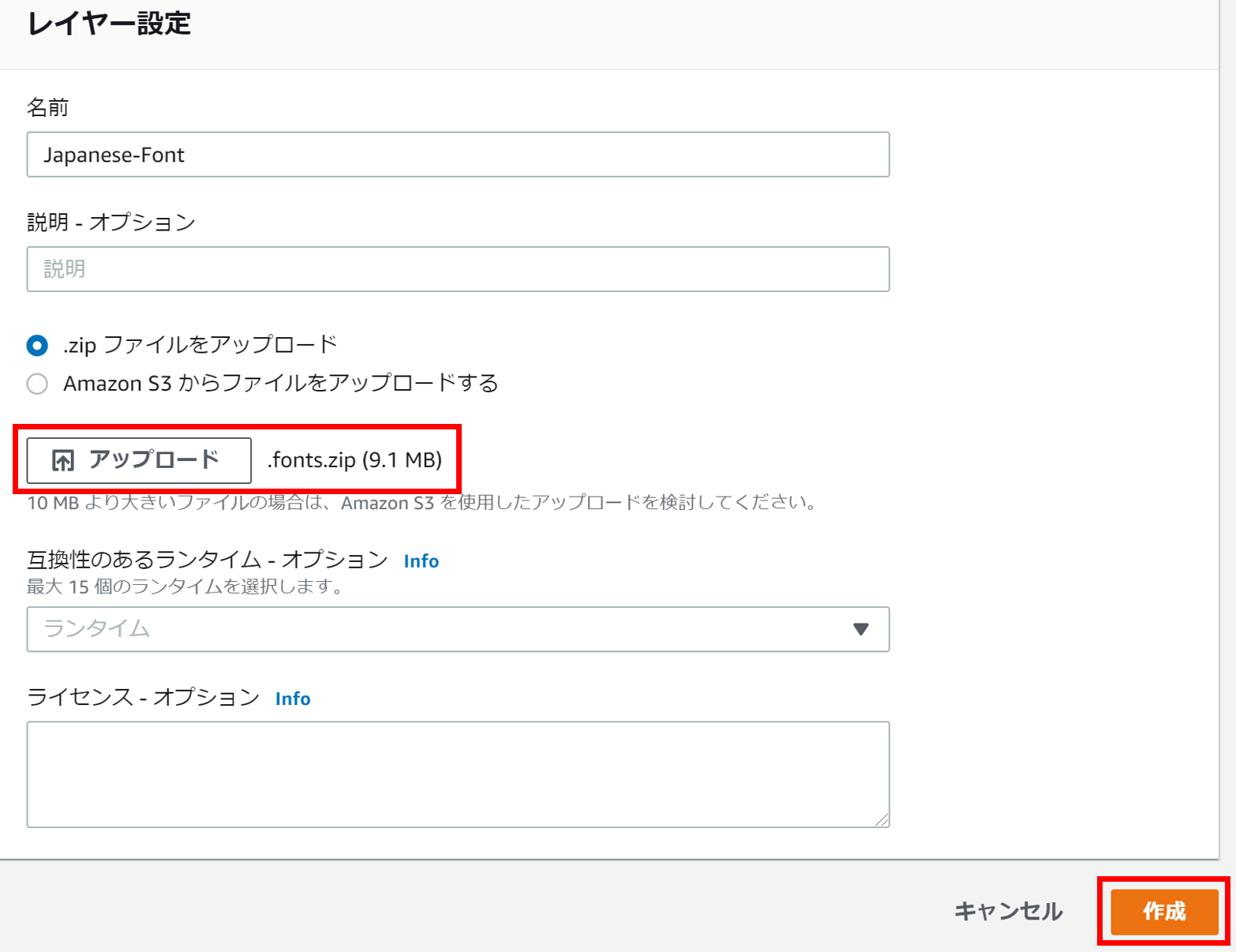
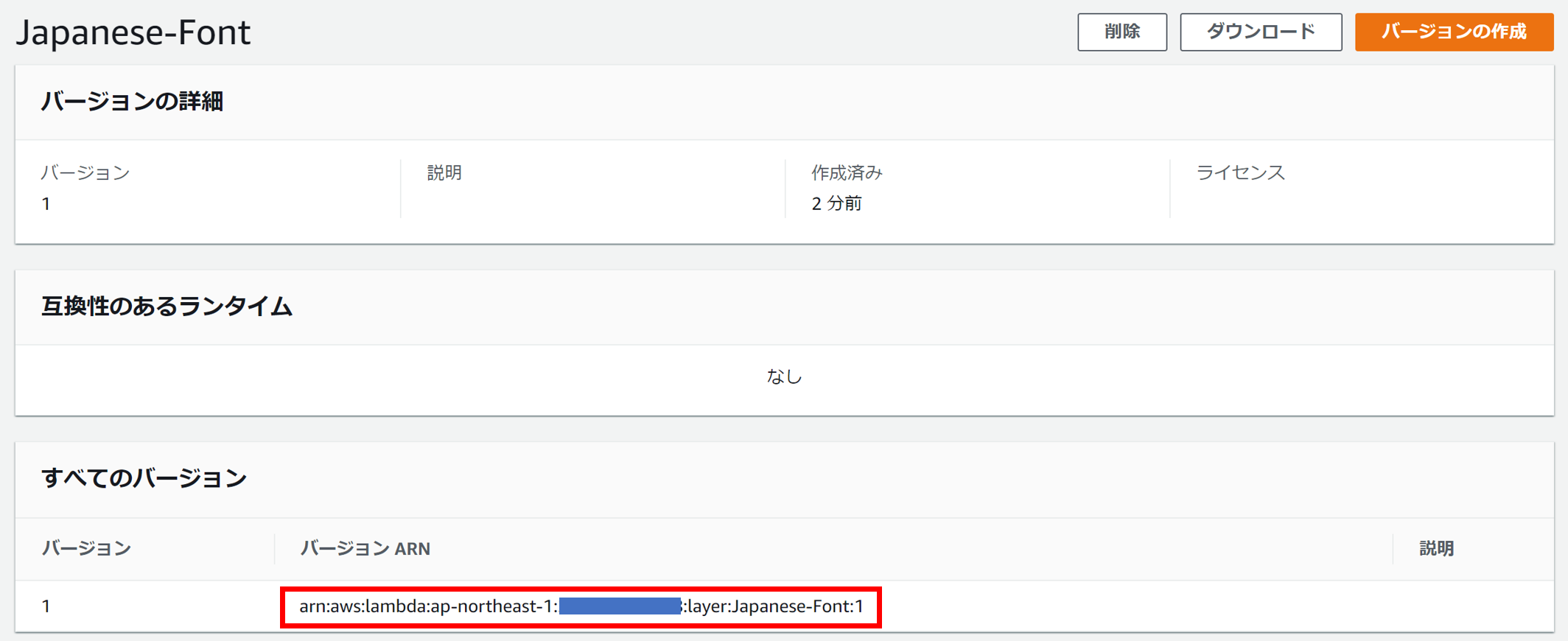
後ほど使用するで作成したレイヤーのArnをメモしておきます。
Lambdaにレイヤーを設定する
Lambdaコンソールから「関数」を選択し、ファンクション名をクリックします。
下のほうに「レイヤーの追加」ボタンがあるので、そこから先ほどメモしたArnを入力して、追加します。
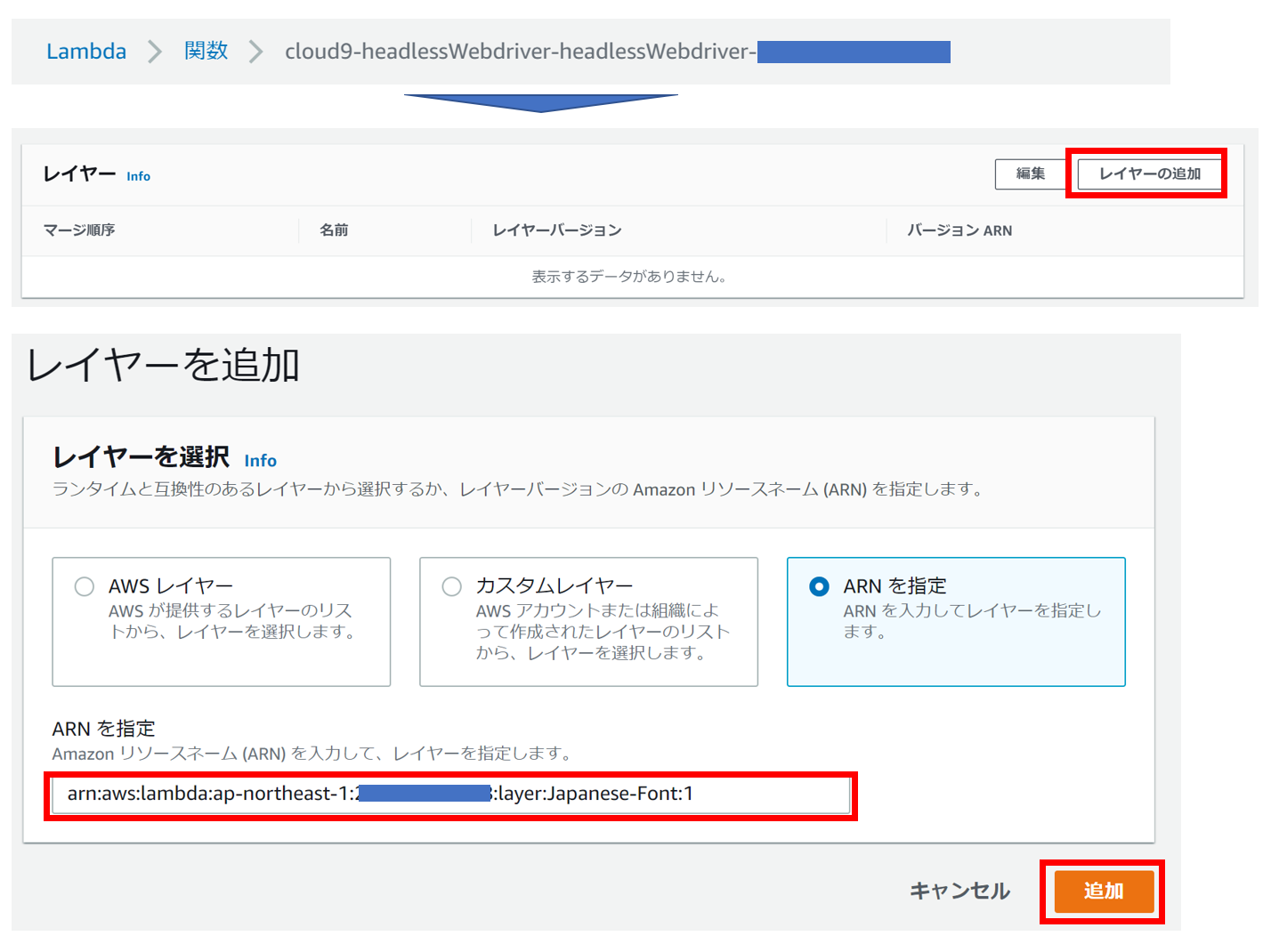
以上でレイヤーの設定は完了です。
レイヤーのポイント
レイヤーはLambda実行環境の「/opt/」配下にzipが展開されます。
このままではLambdaを実行した際に「.fonts」ディレクトリを参照できないので、以下の設定を加える必要があります。
Lambda実行パスを設定
上記はLambdaの実行パスを「/opt」にすることで解消します。
Lambdaコンソールから「関数」を選択し、ファンクション名をクリックします。
「設定」タブの「環境変数」の「編集」をクリックし、環境変数を追加します。
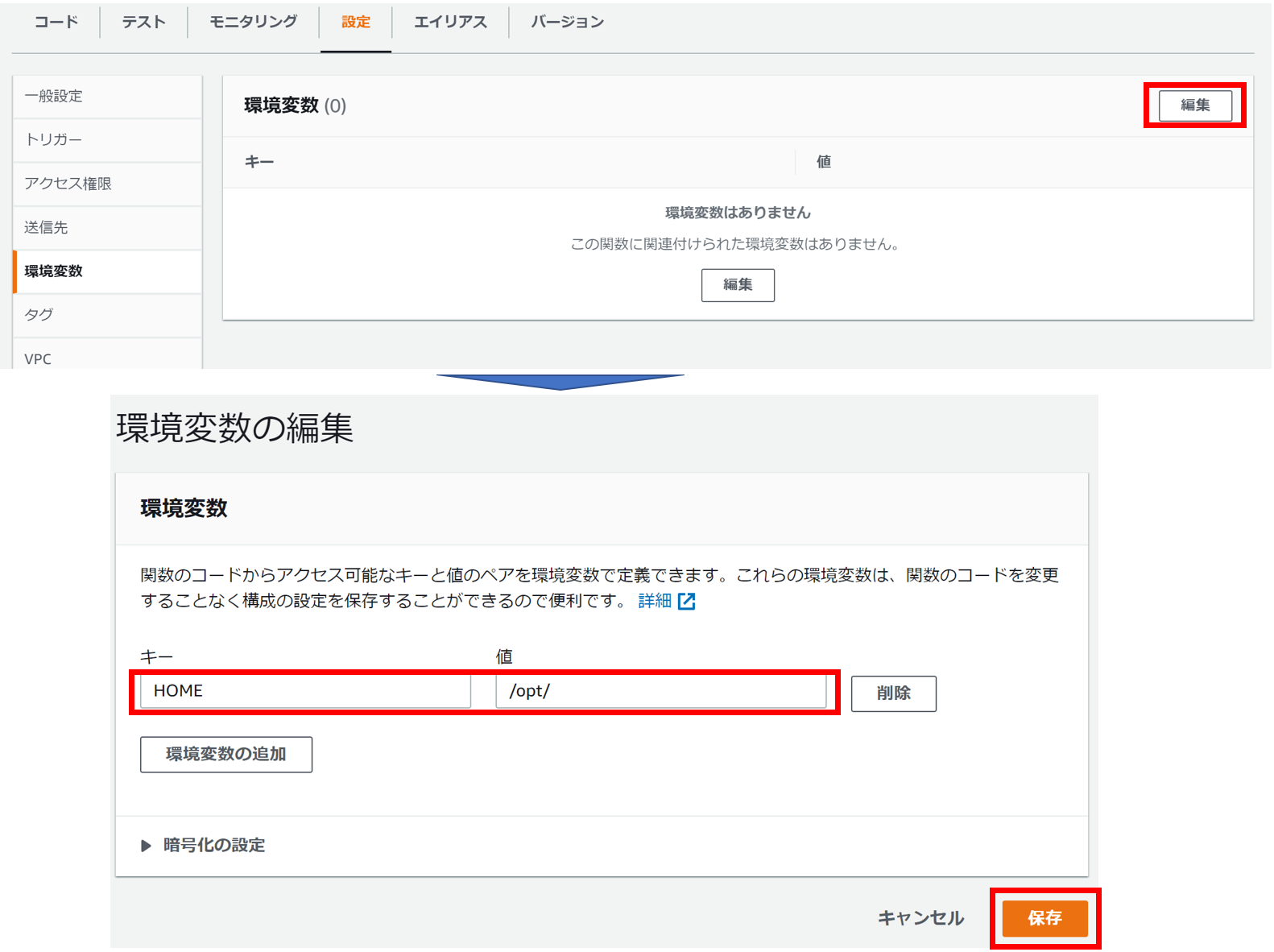
以上で、設定はすべて完了です。
もう一度テスト
上記と同様に、もう一度テストします。

今度は日本語もちゃんと表示できました。
おわりに
本記事では「headless-chromium」の使い方や、Lambdaのレイヤー設定まで多くの内容が含まれます。なにか参考になる箇所があればうれしく思います。



