こんにちは。ドラマーのひろです。
AWS LambdaでLibreOfficeを使った操作を実装したいと思ったことはないでしょうか。
例えば、LibreOfficeを使うことで、WordファイルやPowerPointファイルをPDF化することができます。
LibreOfficeでは多くのファイル形式をPDF化できるので、汎用的なPDFコンバーターとすることができます。
今回はAWS LambdaとLibreOfficeを使用することで安く・保守が不要なPDF変換の仕組みの構築手順を紹介します。
本記事を読むことで以下のメリットがあります。
- 低コストで保守不要なPDF変換の仕組みを構築できる
- AWS LambdaでLibreOfficeを使用するまでの具体的な手順がわかる
- AWS Lambdaでyumパッケージを利用する方法がわかる
- Lambda Layerでpythonライブラリを利用する方法がわかる
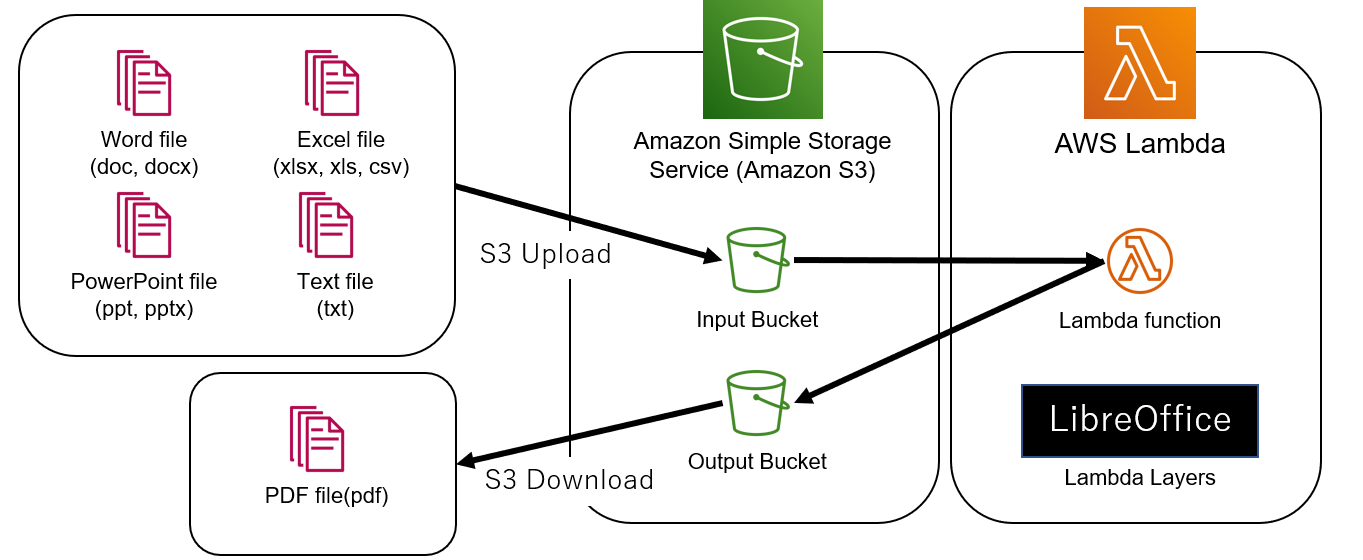
本記事ので紹介する仕組みの構成
今回紹介する構成は以下のように、Word file(doc, docx)、PowerPoint file(ppt, pptx)、Excel file(xlsx, xls, csv)Text file(txt)をS3にアップロードしたとき、アップロードされたファイルをLambdaがLibreOfficeを用いてPDF化し、S3に出力します。
日常的に使用するファイル形式の大半をPDF化することができます。
LibreOfficeは実行モジュールをLambda Layersに追加することで、LambdaからLibreOfficeを実行することが可能となります。
LibreOfficeは本来yumなどでインストールするパッケージで、Lambdaの実行環境には標準で搭載されていません。
今回はLambda Layerとして実行モジュールを追加することで操作できるようにしています。
構築手順(概要)
手順の詳細の前に概要をお伝えします。
本仕組みの構築は以下の流れで進めていきます。
- LibreOfficeのLambdaレイヤーを用意する
- LibreOfficeのモジュールを解凍するために、Pythonライブラリのレイヤーを用意する
- S3バケットを用意する
- Lambdaのコードを記載する
- Lambdaを設定する
通常のLambda構築より複雑な点はLambdaレイヤーの部分です。
まずはLinuxでLibreOfficeを使ってみる
具体的な構築手順に入る前に、LinuxでLibreOfficeを実際に使ってみることで何ができるか体感できます。
ただし、すでにLibreOfficeを使ったことがある方や、Lambda構築にすぐ取り掛かりたい方には不要なので、次の章にスキップして構いません。
Linux(CentOS)へのLibreOffice導入手順
RPMのURLを取得
LibreOffice公式サイトから最新版のLibreOfficeをダウンロードリンクを取得します。
下記のように、ダウンロードボタンの遷移先で「リンクのアドレスをコピー」することで、URLをコピーすることができます。
OSの選択項目は、「Linux(64bit)(rpm)」を選択してください。
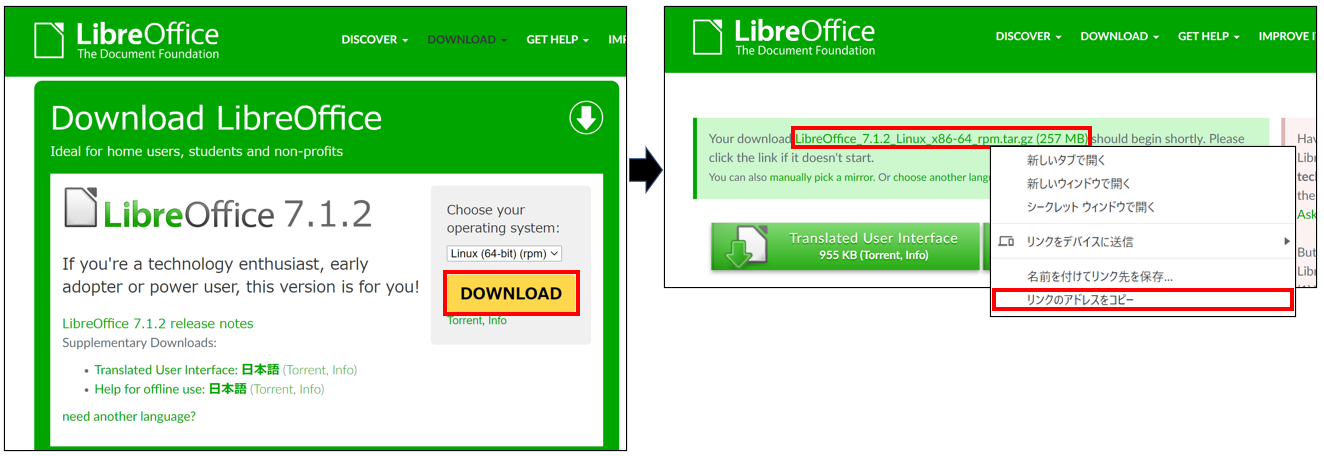
取得したURLは以下のようなURLになっているはずです。「https://download.documentfoundation.org/libreoffice
/stable/7.1.2/rpm/x86_64/LibreOffice_7.1.2_Linux_x86-64_rpm.tar.gz」
RPMをダウンロード
取得したリンクを使用して、RPMをダウンロードします。
Linuxのコマンドラインで以下を実行します。
$ sudo wget 【取得したURL】URLを入れた例は以下の通りです。
$ sudo wget https://download.documentfoundation.org/libreoffice/stable/7.1.2/rpm/x86_64/LibreOffice_7.1.2_Linux_x86-64_rpm.tar.gzこれによって、「LibreOffice….tar.gz」というファイルが手に入りました。
これを以下のコマンドで解凍します。
$ sudo tar -zxvf 【ファイル名(LibreOffice.....tar.gz)】解凍したディレクトリの中に「RPMS」ディレクトリが入っており、その中に.rpmファイルが複数存在することを確認できれば大丈夫です。
うまく解凍できない場合は、URLが間違っていた可能性が高いです。ファイルサイズなど確認して正しくダウンロードできたか確認してみてください。
LibreOfficeをインストール
ダウンロードしたRPMを使用して、LibreOfficeをインストールします。
以下のコマンドを実行してください。
$ sudo yum install 【解凍したディレクトリ】/RPMS/*.rpmコマンドの実行例は以下の通りです。
$ sudo yum install LibreOffice_7.1.2.2_Linux_x86-64_rpm/RPMS/*.rpmここで、「libcairo.so.2」がないというエラーが出る場合があります。
その場合は、cairoをインストールしてから実行するとうまくいくはずです。
$ sudo yum install -y cairoLibreOfficeをコマンドから使ってみる
それではいよいよLibreOfficeを使ってみます。
使用するコマンドは以下になります。
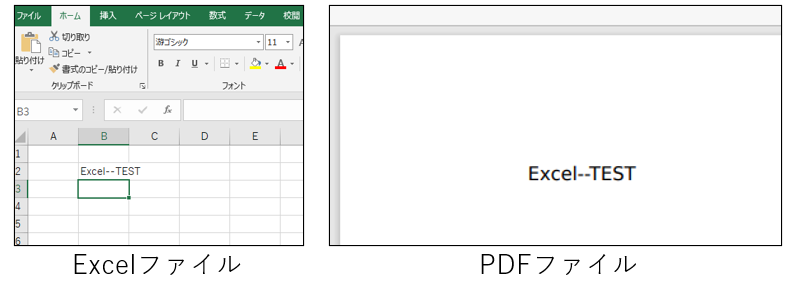
$ libreoffice7.1 --headless --convert-to pdf:writer_pdf_Export --outdir 【出力先ディレクトリ】 【変換するファイル】libreoffice7.1の「7.1」はバージョンによって異なります。
もしくは、実行ファイルをそのまま指定しても実行できます。「例:/opt/libreoffice7.1/program/soffice.bin」
コマンドの実行例は以下の通りです。
$ libreoffice7.1 --headless --convert-to pdf:writer_pdf_Export --outdir /tmp ./TEST.xlsxこれにより、LinuxのコマンドラインからPDF化できることを確認できました。
AWS LambdaでLibreを実行する
それでは冒頭で取り上げたLambdaでLibreを実行する仕組みを構築していきます。
上記の構成図と手順概要を再掲します。
- LibreOfficeのLambdaレイヤーを用意する
- LibreOfficeのモジュールを解凍するために、Pythonライブラリのレイヤーを用意する
- S3バケットを用意する
- Lambdaのコードを記載する
- Lambdaを設定する
LibreOfficeのLambdaレイヤーを用意する
LibreOfficeのようにyumでインストールしなければならないようなパッケージは、Lambdaの実行環境にはもともと入っていません。
そこで、下記2つのいずれかの方法で実行モジュールをLambdaの実行環境に加える必要があります。
- Lambdaのソースコードと一緒に実行モジュールをzipとして固めてLambdaにアップロードする
- Lambdaレイヤーに実行モジュールをアップロードしてLambdaにLambdaレイヤーを接続する
このうち、以下の理由からLambdaレイヤーを使う方法をオススメします。
- ソースコードをzipに固めると、Lambdaコンソール画面からソースコードの変更ができなくなり、コードを変更するたびzipに固める必要がある
- Lambdaレイヤーを一度作成しておけば、別のLambdaで使用したいときに使いまわしができる
また、Lambdaレイヤーは先人が作成し、公開されているものも数多くあります。
まずはLambdaレイヤーが公開されているか調べてみることをオススメします。
今回も、先人が作成したLambdaレイヤーを使わせてもらうことにしました。
こちらのgithubに情報が記載されているので、まずは開いてみてください。
こちらのgithubを使用するうえで意識したいポイントは以下となります。
- Lambdaレイヤーのリージョンを確認する
- 実行環境がAmazon LinuxかAmazon Linux2か確認する
- 圧縮形式はbrotliを使用する
上記のポイントをひとつずつ解説していきます。
Lambdaレイヤーのリージョンを確認する
LambdaのリージョンとLambdaレイヤーのリージョンは同一である必要があります。
githubを見てみると、残念ながら東京リージョン(ap-northeast-1)はありませんね。
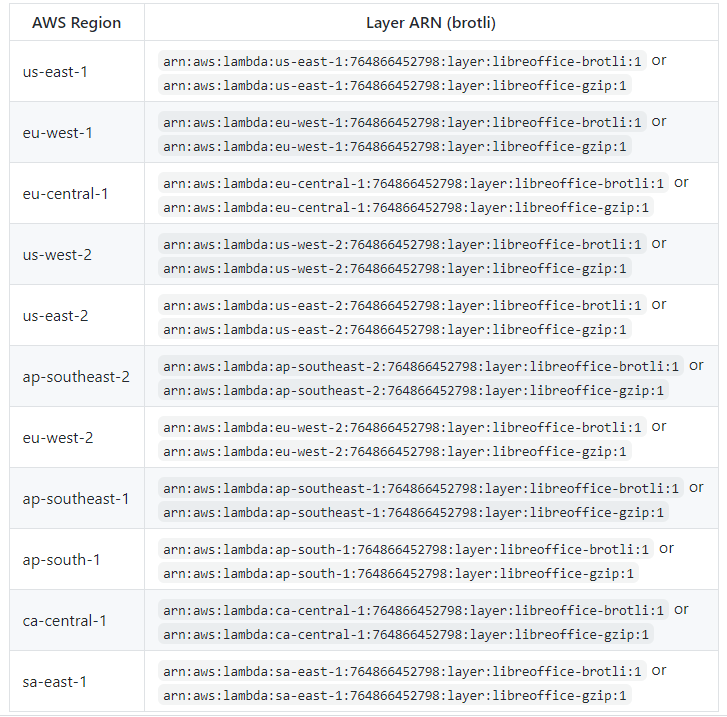
普段は東京リージョンを使っていますが、今回はバージニア北部(us-east-1)にLambdaを作成することにしました。
実行環境がAmazon LinuxかAmazon Linux2か確認する
Lambdaのラインタイムによって、Lambdaの実行OSがAmazon Linuxか、Amazon Linux2か変わってくるようです。

例えば、pythonの場合3.8以外はAmazon Linuxです。
今回はpython3.6でLambdaを作成するつもりなので、LambdaのOSはAmazon Linuxということになります。
そのため、使用するレイヤーは「LibreOffice v6.4.0.1 」ではなく、「LibreOffice 6.1.0.0.alpha0」のレイヤーを使用しなければならないということです。
そこで、今回は「us-east-1」の「LibreOffice 6.1.0.0.alpha0」である「arn:aws:lambda:us-east-1:764866452798:layer:libreoffice:8」のArnを使用することにしました。
一度ここを間違えており、「No Module Named ‘_cffi_backend’」エラーに悩まされました。
圧縮形式はbrotliを使用する
こちらのLambdaレイヤーを使用するうえで一番ハマるポイントがここです。
こちらのGithubではLibreOfficeをgzipとbrotliの2パターンで圧縮した実行モジュールを提供してくれています。(LibreOffice v6.4.0.1のみ)

しかし、こちらのgzipで固めている実行モジュールは内部が破損しているのか、解凍したモジュールがうまく動きません。
そのため、brotliで圧縮されたモジュールを使用することになります。
今回はLibreOffice 6.1.0.0.alpha0なので、brotliしか選択肢がありませんが、別件で使用する際にハマりました。
Stackoverflowでもハマっている方がとても多く、結論としてはbrotliを使いましょうということでした。
LibreOfficeのLambdaレイヤーを接続する
それでは上記の通り「arn:aws:lambda:us-east-1:764866452798:layer:libreoffice:8」をLambdaレイヤーとして設定します。
まずは、バージニア北部(us-east-1)にLambda関数を作成します。
関数を作成したのち、以下のようにLambdaレイヤーを追加できます。
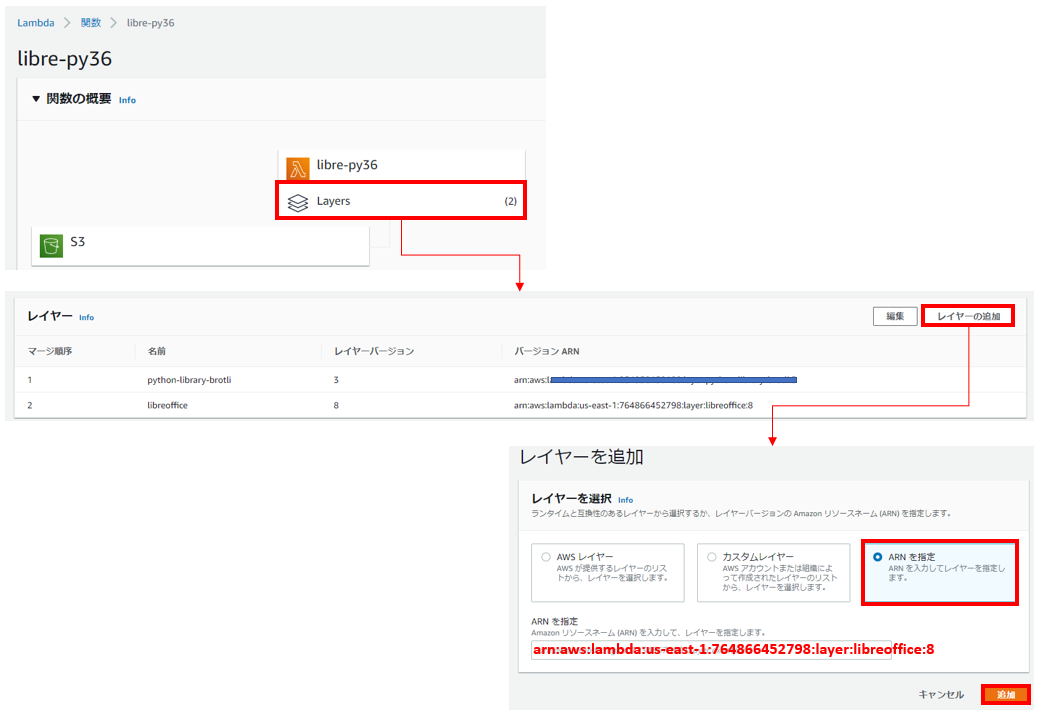
LibreOfficeのモジュールを解凍するために、Pythonライブラリのレイヤーを用意する
上記のようにLambdaレイヤーはbrotliで圧縮された実行モジュールを使用するため、brotliを解凍するためのpythonライブラリを使用する必要があります。
下記コマンドからbrotliライブラリを固めたzipを作成します。
(こちらは、Lambdaランタイムと同じバージョンのpythonが入っている環境で実行するのが良いです。今回はpython3.6です。できればOSも合わせるとさらに良いです。)
$ mkdir brotli
$ python -m pip install --target=./brotli brotlipy
$ zip brotli -r brotlipythonライブラリの名前は「brotlipy」です。「brotli」というライブラリもあるので注意してください。
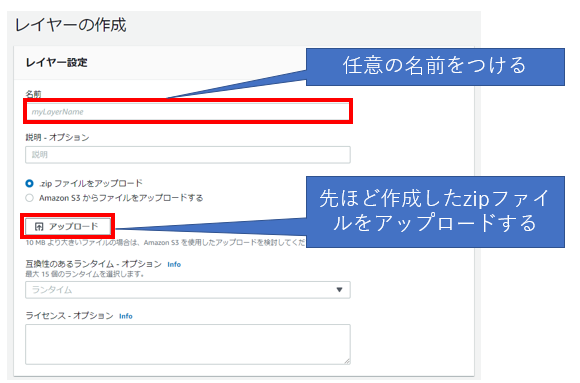
zipファイルが作成出来たら、Lambdaレイヤーを作成していきます。
Lambdaコンソール左側のタブから「レイヤー」をクリックし、「レイヤーの作成」をクリックします。

その後、任意の名前を付けて、先ほど作成したzipファイルをアップロードすれば完了です。
Lambdaレイヤー作成後にArnが表示されるのでメモしておき、上記と同様にLambdaにLambdaレイヤーを接続します。
Lambdaレイヤーとしてアップロードしたzipは、Lambda実行時には解凍された状態で/opt/配下に置かれています。
S3バケットを用意する
次に、LambdaのトリガーとなるS3バケットとPDF化したファイルを配置するS3バケットを作成します。
Lambdaと同じリージョンに任意の名前で作成してください。
トリガーとするバケットとPDFファイルを配置するバケットは分けた方が良いです。
同一のバケットにするとPDF化されたファイルが置かれるときに再度トリガーされてLambdaの処理が起きる可能性があります。
バケットができたら、Lambdaのトリガーとして設定していきます。
Lambda関数画面の「トリガーを追加」から先ほど作成したトリガー用のバケットを指定します。
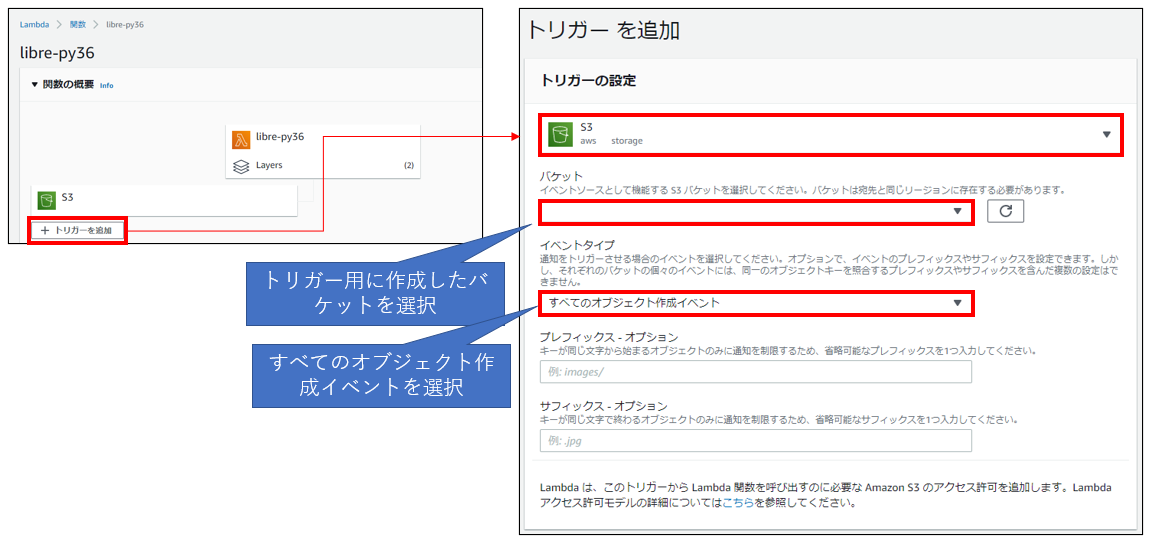
Lambdaのコードを記載する
ここまでで、Lambda関数のコードを書くための準備がすべて整いました。
コードは以下をコピーしてもらえれば、そのまま使えます。
import subprocess
import tarfile
import sys
from io import BytesIO
import os
import time
import boto3
import urllib.parse
import json
sys.path.append("/opt/brotli")
import brotli
ACCESS_KEY = "XXXXXXXXXXXXXXXX"
SECRET_ACCESS_KEY = "XXXXXXXXXXXXXXXX"
def extract_libre_office():
buffer = BytesIO()
with open('/opt/lo.tar.br', mode='rb') as fout:
file = fout.read()
buffer.write(brotli.decompress(file))
buffer.seek(0)
with tarfile.open(fileobj=buffer) as tar:
tar.extractall('/tmp')
def lambda_handler(event, context):
if os.path.exists("/tmp/instdir/program/soffice.bin"):
pass
else :
# load libre
extract_libre_office()
# Get Trigger event
if 'Records' in event.keys():
input_bucket = event['Records'][0]['s3']['bucket']['name']
output_bucket = "XXXXXXXXXXXXXXXX"
input_key = urllib.parse.unquote_plus(event['Records'][0]['s3']['object']['key'], encoding='utf-8')
s3 = boto3.client('s3', aws_access_key_id=ACCESS_KEY, aws_secret_access_key=SECRET_ACCESS_KEY)
else :
return 'test finished'
# get S3 Object
file_path = '/tmp/'+input_key
s3.download_file(input_bucket, input_key, file_path)
# Document -> pdf
proc = subprocess.run("/tmp/instdir/program/soffice.bin --headless --norestore --invisible --nodefault --nofirststartwizard --nolockcheck --nologo --convert-to pdf:writer_pdf_Export --outdir /tmp {}".format("/tmp/"+input_key), shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
print('STDOUT: {}'.format(proc.stdout))
print('STDERR: {}'.format(proc.stderr))
# get pdf path
key_list = input_key.split('.')
pdf_path = "/tmp/"+input_key.replace(key_list[-1], 'pdf')
# put S3 Object
if os.path.exists(pdf_path):
print('PDF: {}'.format(pdf_path.replace("/tmp/", "")))
print('Size: {}'.format(os.path.getsize(pdf_path)))
data = open(pdf_path, 'rb')
s3.put_object(Bucket=output_bucket, Key=pdf_path.replace("/tmp/", ""),Body=data)
data.close()
else :
print("The PDF file({}) cannot be found".format(pdf_path))
return ''
以下の変数だけ、変更して使ってください。
- ACCESS_KEY: S3へのアクセス権限を持ったIAMユーザのアクセスキー
- SECRET_ACCESS_KEY: S3へのアクセス権限を持ったIAMユーザのシークレットキー
- output_bucket: PDF出力先バケットの名前
Lambdaを設定する
ここまでくれば、あと一息です。
Lambda関数の設定からメモリとタイムアウト値を上げておきます。
というのも、今回の処理でbrotliの解凍処理がかなり重いため、初回起動時だけかなりメモリを使用し、処理も時間がかかるためです。

およそ1500MBくらいメモリがあれば十分そうでした。
タイムアウトも5分あれば十分そうですが、余裕を見て10分にしています。
また、初回に実行したときor前回の実行から間隔が空いたときにうまくいかない場合があります。
これはbrotliの解凍が途中になっているため、LibreOfficeがうまく実行できていないためだと思われます。
処理が成功しているか確認するためには、Lambda関数画面の「モニタリング」から「ログ」をクリックし、CloudWatch logsのログを見てください。
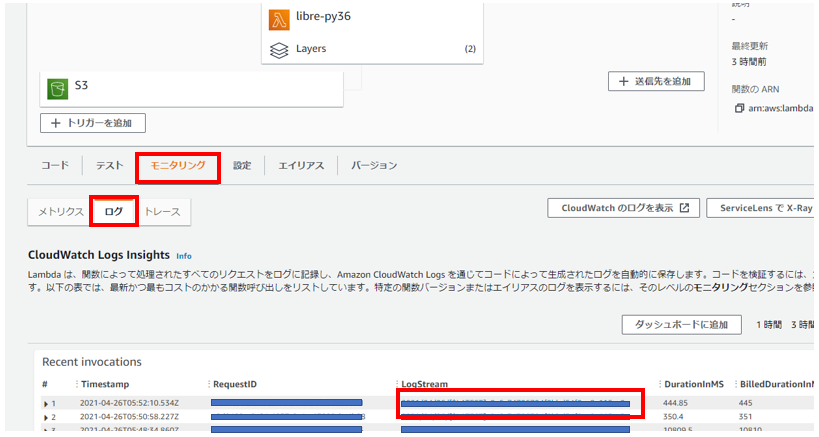
以下のようにSTDOUTもSTDERRもどちらも何も出力されていないときは処理が失敗しています。
成功しているときにはSTDOUTに結果が出力されるはずです。

このような状況を回避するには、Lambdaのウォームアップが必要です。
方法としては以下の2パターンあります。
- Lambdaを定期実行する
- Lambdaの「プロビジョニングされた同時実行設定」をする
Lambdaの定期実行はトリガーに新しく定期実行用にCloudWatchを設定すれば問題ありません。
もしくは、Lambda関数画面の「設定」から「同時実行」をクリックし、「プロビジョニングされた同時実行設定」を追加することで、Lambdaの実行環境がリセットされずに残しておくこともできます。
「プロビジョニングされた同時実行設定」はLambda実行用の環境を待機させておくということなので、費用が大きくかかります。
私の場合、20ドル/月程度かかりそうでした。
いざ実行する
では、出来上がった仕組みを実行してみます。
トリガー用のS3バケットにファイルを置くことで、PDF化されたファイルが配置用のバケットに置かれているではないでしょうか。
もしPDFが置かれていないときは上記のようにログを確認してください。
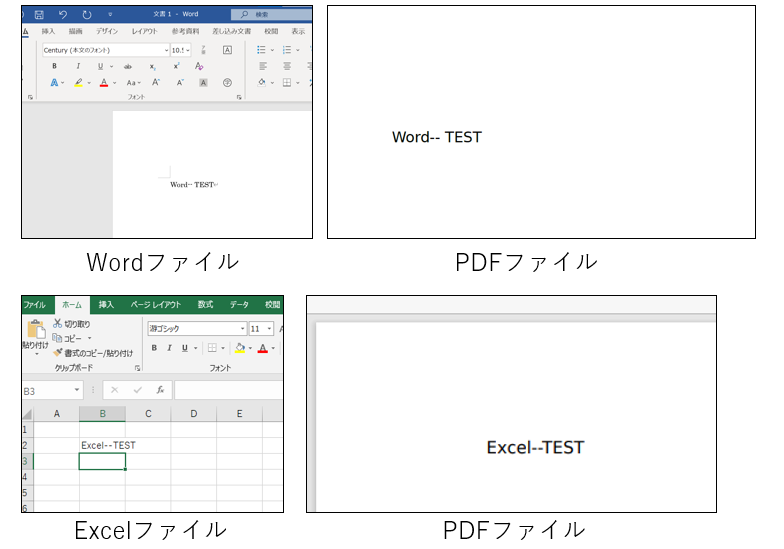
以下は一部ですが、テスト用に試したファイルです。
Word、Excel、PowerPoint、TXTのファイルをPDF化することができました。

おまけ
今回の仕組みで日本語のドキュメントをPDFに変換した際、文字化けしてしまったという方がいらっしゃるかもしれません。
その場合は、日本語のフォントをLambdaレイヤーで追加することでうまくいきます。
具体的な手順は以下の記事の中で解説しているので参照してみてください。



